usedata <- read.csv(
#csvファイルならURL突っ込んでも持ってこれるよ
"http://r-marketing.r-forge.r-project.org/data/rintro-chapter4.csv",
stringsAsFactors = TRUE)
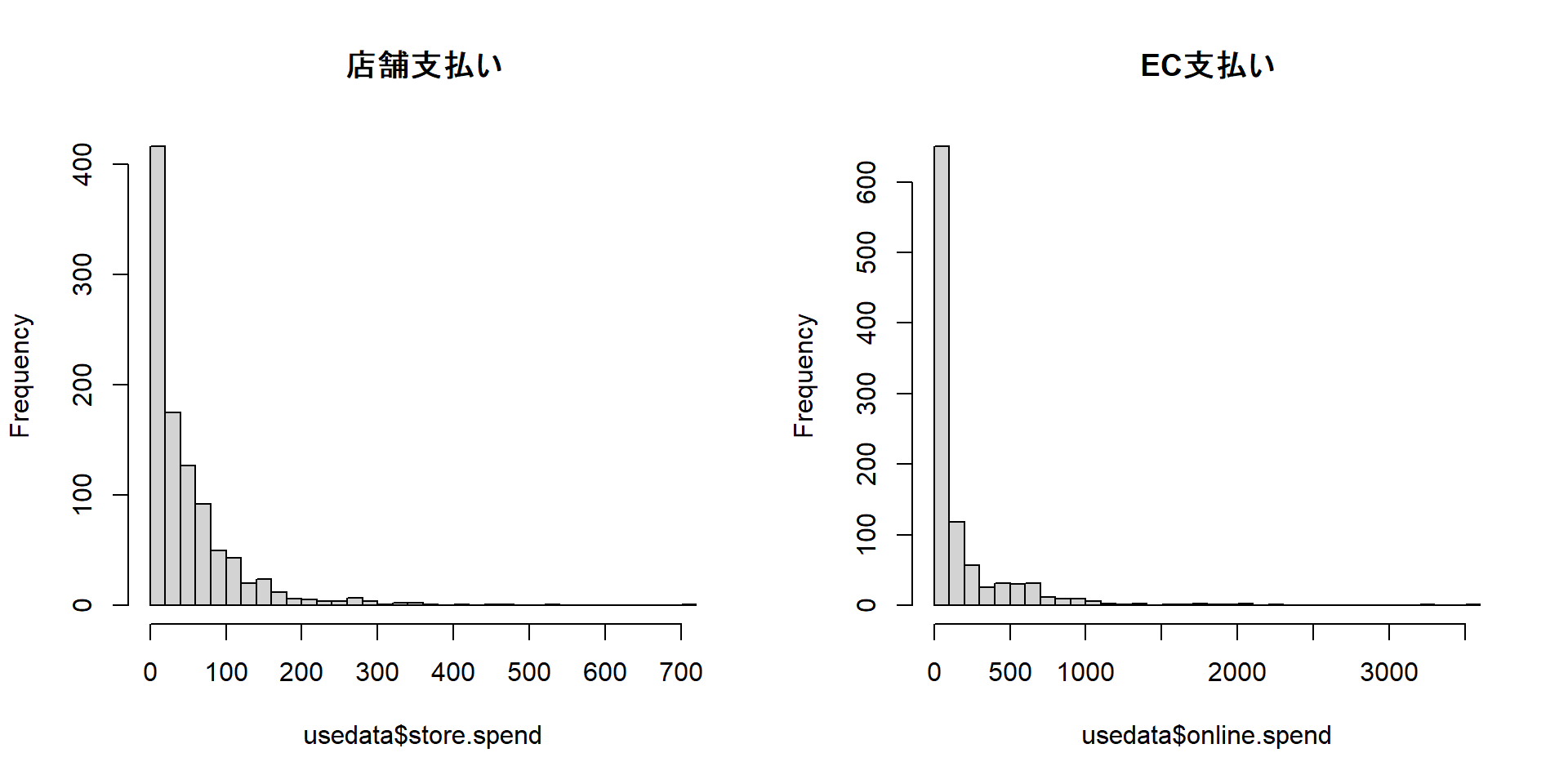
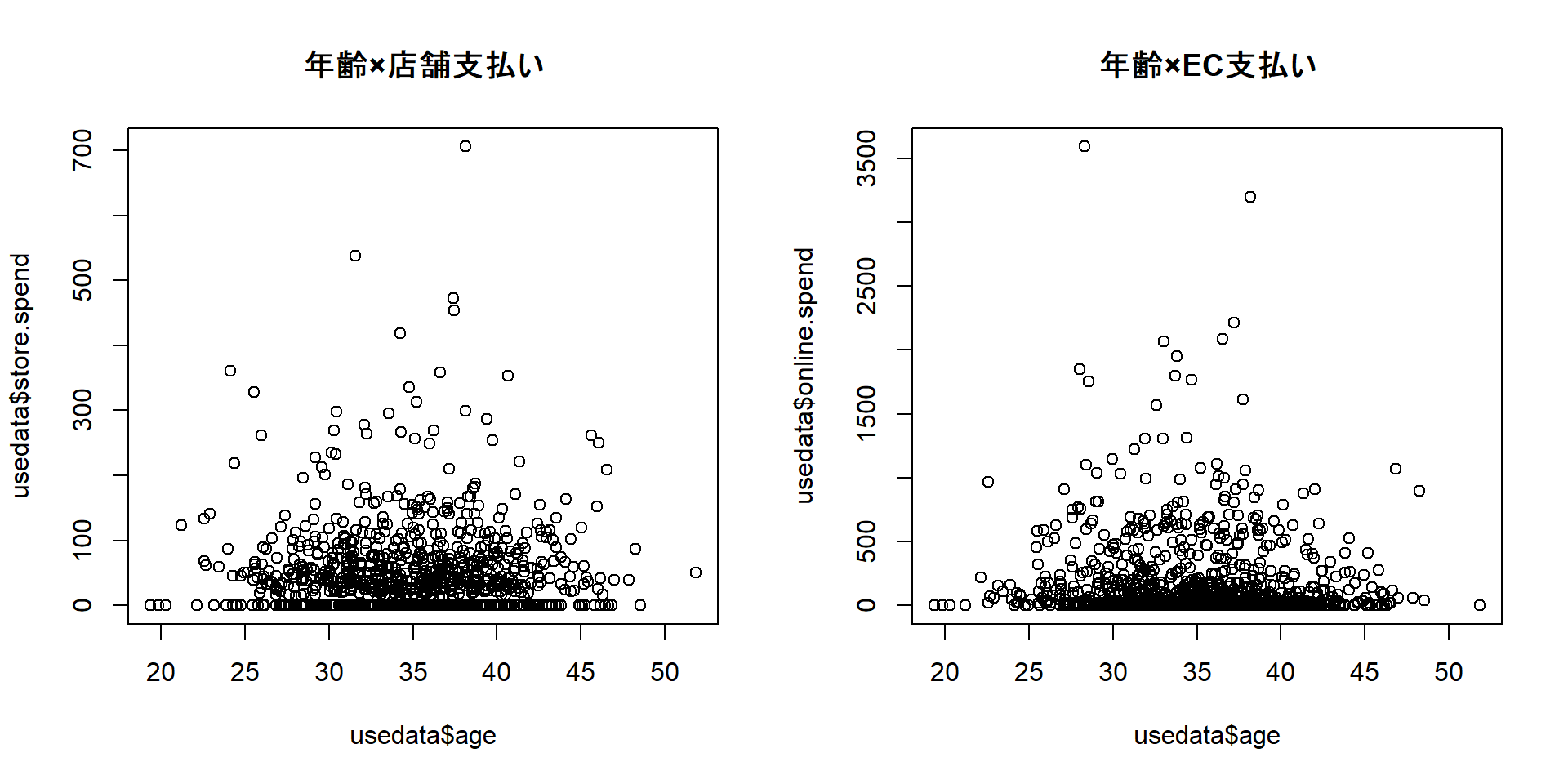
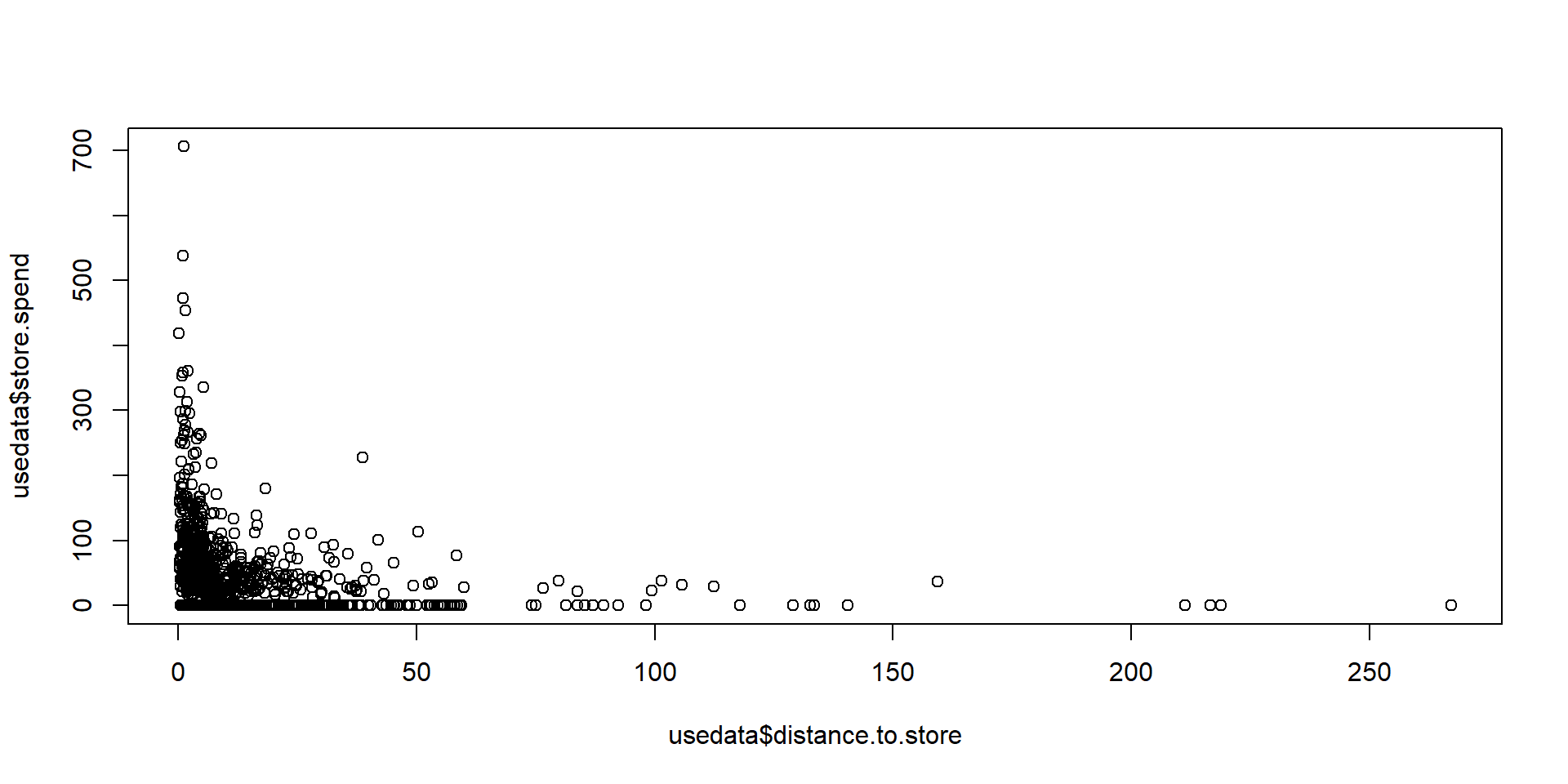
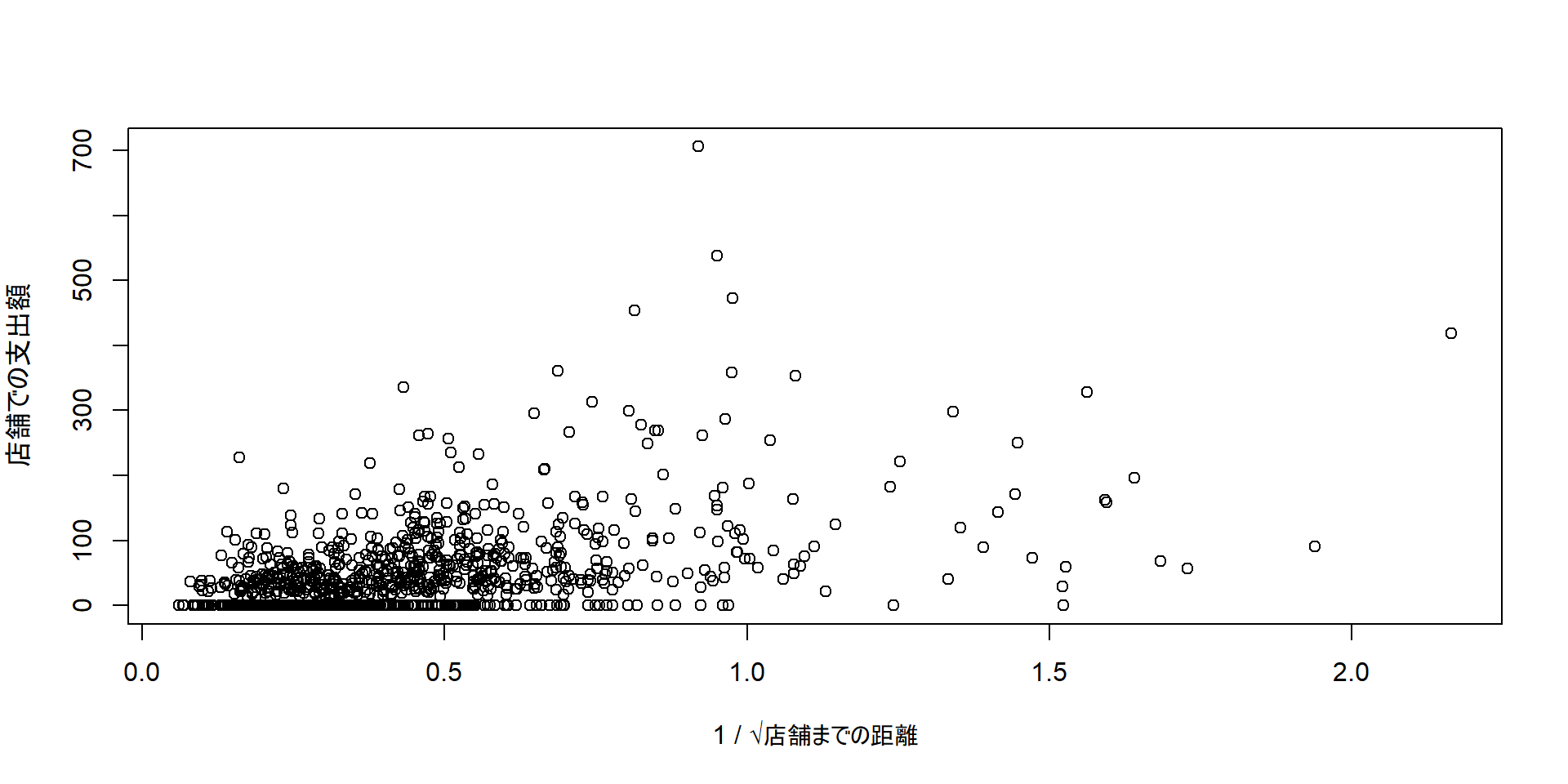
head(usedata, n = 5) # 先頭5行だけ見る cust.id age credit.score email distance.to.store online.visits
1 1 22.89437 630.6089 yes 2.582494 20
2 2 28.04994 748.5746 yes 48.175989 121
3 3 35.87942 732.5459 yes 1.285712 39
4 4 30.52740 829.5889 yes 5.253992 1
5 5 38.73575 733.7968 no 25.044693 35
online.trans online.spend store.trans store.spend sat.service sat.selection
1 3 58.42999 4 140.32321 3 3
2 39 756.88008 0 0.00000 3 3
3 14 250.32801 0 0.00000 NA NA
4 0 0.00000 2 95.91194 4 2
5 11 204.69331 0 0.00000 1 1